
In this blog post, we present a high-level description of the methodology underpinning these feeds, which we have documented in more detail in a paper available on ArXiv.
Problem
Given historical and recent customers’ interactions, what are the most relevant items to display on the home page of every customer from a given set of items such as promotional items or newly released items? To answer this question at scale, there are four challenges that we needed to overcome:
- Customer representation challenge – Bol has more than 13 million customers with diverse interests and interaction behavior. How do we develop customer profiles?
- Item representation challenge – Bol has more than 40 million items for sale, each having its own rich metadata and interaction data. How do we represent items?
- Matching challenge – how do we efficiently and effectively match interaction data of 13 million customers with potentially 40 million items?
- Ranking challenge – In what order do we show the top N items per customer from a given set of relevant item candidates?
In this blog, we focus on addressing the first three challenges.
Solution
To address the three of the four challenges mentioned above, we use embeddings. Embeddings are floating point numbers of a certain dimension (e.g. 128). They are also called representations or (semantic) vectors. Embeddings have semantics. They are trained so that similar objects have similar embeddings, while dissimilar objects are trained to have different embeddings. Objects could be any type of data including text, image, audio, and video. In our case, the objects are products and customers. Once embeddings are available, they are used for multiple purposes such as efficient similarity matching, clustering, or serving as input features in machine learning models. In our case, we use them for efficient similarity matching. See Figure 1 for examples of item embeddings.

Figure 1: Items in a catalog are represented with embeddings, which are floating numbers of a certain dimension (e.g. 128). Embeddings are trained to be similar when items have common characteristics or serve similar functions, while those that differ are trained to have dissimilar embeddings. Embeddings are commonly used for similarity matching. Any type of data can be embedded. Text (language data), tabular data, image, and audio can all be embedded either separately or jointly.
The common approach to using embeddings for personalization is to rely on a user-item framework (see Figure 2). In the user-item framework, users and items are represented with embeddings in a shared embedding space. Users have embeddings that reflect their interests, derived from their historical searches, clicks and purchases, while items have embeddings that capture the interactions on them and the metadata information available in the catalog. Personalization in the user-item framework works by matching user embeddings with the index of item embeddings.
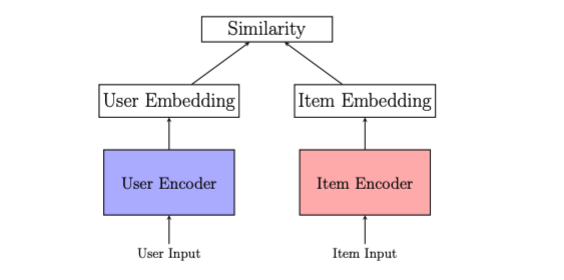
Figure 2: User-to-item framework: Single vectors from the user encoder limit representation and interpretability because users have diverse and changing interests. Keeping user embeddings fresh (i.e.capturing most recent interests) demands high-maintenance infrastructure because of the need to run the embedding model with most recent interaction data.
We started with the user-item framework and realized that summarizing users with single vectors has two issues:
- Single vector representation bottleneck. Using a single vector to represent customers introduces challenges due to the diversity and complexity of user interests, compromising both the capacity to accurately represent users and the interpretability of the representation by obscuring which interests are represented and which are not.
- High infrastructure and maintenance costs. Generating and maintaining up-to-date user embeddings requires substantial investment in terms of infrastructure and maintenance. Each new user action requires executing the user encoder to generate fresh embeddings and the subsequent recommendations. Furthermore, the user encoder must be large to effectively model a sequence of interactions, leading to expensive training and inference requirements.
To overcome the two issues, we moved from a user-to-item framework to using an item-to-item framework (also called query-to-item or query-to-target framework). See Figure 3. In the item-to-item framework, we represent users with a set of query items. In our case, query items refer to items that customers have either viewed or purchased. In general, they could also include search queries.

Figure 3: Query-to-item framework: Query embeddings and their similarities are precomputed. Users are represented by a dynamic set of queries that can be updated as needed.
Representing users with a set of query items provides three advantages:
- Simplification of real-time deployment: Customer query sets can dynamically be updated as interactions happen. And this can be done without running any model in real-time. This is possible because all items in the catalog are known to be potential view or buy queries, allowing for the pre-computation of results for all queries.
- Enhanced interpretability: Any personalized item recommendation can be traced back to an item that is either viewed or purchased.
- Increased computational efficiency: The queries that are used to represent users are shared among users. This enables computational efficiency as the query embeddings and their respective similarities can be re-used once computed for any customer.
Pfeed – A method for generating personalized feed
Our method for creating personalized feed recommendations, which we call Pfeed, involves four steps (See Figures 4).
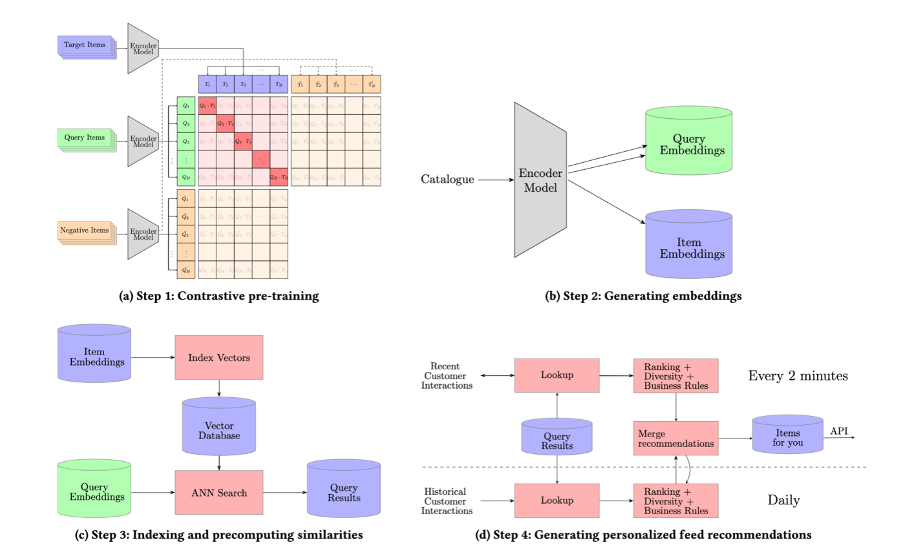
Figure 4: The major steps involved in generating near real-time personalized recommendations
Step 1 is about training a transformer encoder model to capture the item-to-item relationships shown in Figure 5. Here, our innovation is that we use three special tokens to capture the distinct roles that items play in different contexts: view query, buy query and, target item.
View queries are items clicked during a session leading to the purchase of specific items, thus creating view-buy relationships. Buy queries, on the other hand, are items frequently purchased in conjunction with or shortly before other items, establishing buy-buy relationships.
We refer to the items that follow view or buy queries as target items. A transformer model is trained to capture the three roles of an item using three distinct embeddings. Because our model generates the three embeddings of an item in one shot, we call it a SIMO model (Single Input Multi Output Model). See paper for more details regarding the architecture and the training strategy.
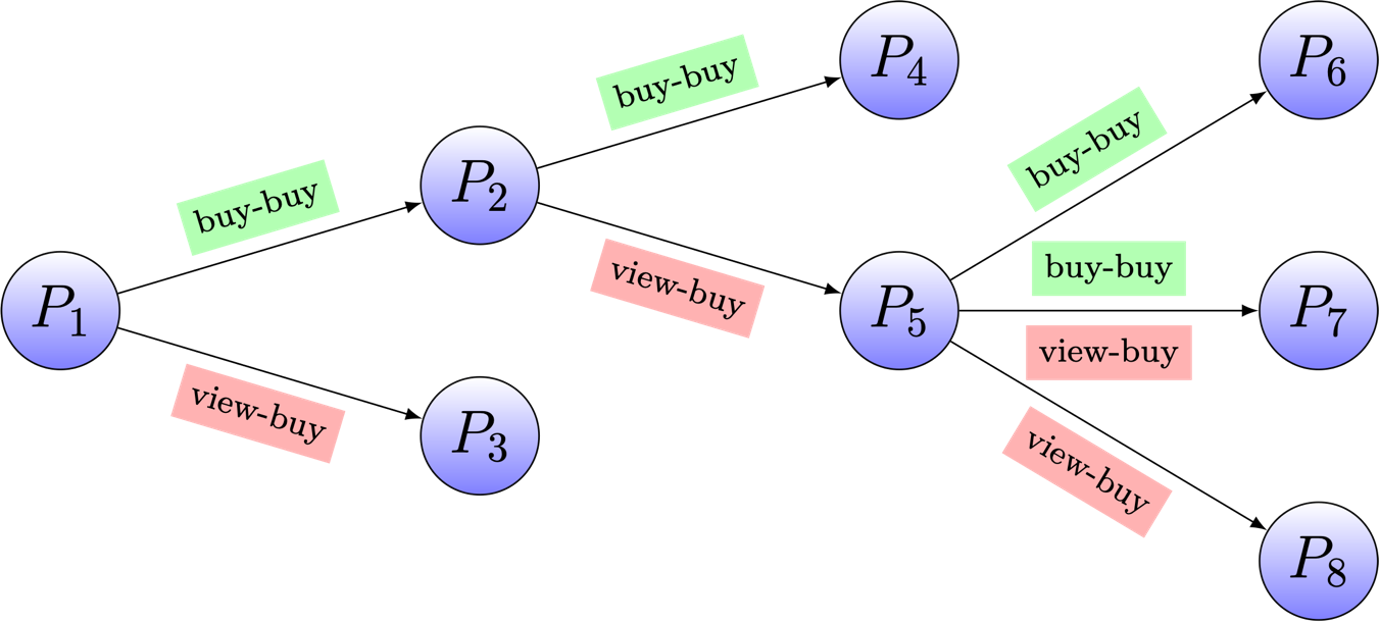
Figure 5: Product relationships: most customers that buy P_2 also buy P_4, resulting into a buy-buy relationship. Most customers that view product P_2 end up buying P_5, resulting into a view-buy relationship. In this example, P_2 plays three types of roles – view query, buy query ,and target item. The aim of training an encoder model is to capture these existing item-to-item relationships and then generalize this understanding to include new potential connections between items, thereby expanding the graph with plausible new item-to-item relationships.
Step 2 is about using the transformer encoder trained in step 1 and generating embeddings for all items in the catalog.
Step 3 is about indexing the items that need to be matched (e.g. items with promotional labels or items that are new releases). The items that are indexed are then matched against all potential queries (viewed or purchased items). The results of the search are then stored in a lookup table.
Step 4 is about generating personalized feeds per customer based on customer interactions and the lookup table from step 3. The process for generating a ranked list of items per user includes: 1) selecting queries for each customer (up to 100), 2) retrieving up to 10 potential next items- to-buy for each query, and 3) combining these items and applying ranking, diversity, and business criteria (See Figure 4d). This process is executed daily for all customers and every two minutes for those active in the last two minutes. Recommendations resulting from recent queries are prioritized over those from historical ones. All these steps are orchestrated with Airflow.
Applications of Pfeed
We applied Pfeed to generate various personalized feeds at Bol, viewable on the app or website with titles like Top deals for you, Top picks for you, and New for you. The feeds differ on at least one of two factors: the specific items targeted for personalization and/or the queries selected to represent customer interests. There is also another feed called Select Deals for you. In this feed, items with Select Deals are personalized exclusively for Select members, customers who pay annual fees for certain benefits. You can find Select Deals for you on empty baskets.
In general, Pfeed is designed to generate”X for you” feed by limiting the search index or the search output to consist of only items belonging to category 𝑋 for all potential queries.
Evaluation
We perform two types of evaluation – offline and online. The offline evaluation is used for quick validation of the efficiency and quality of embeddings. The online evaluation is used to assess the impact of the embeddings in personalizing customers’ homepage experiences.
Offline evaluation
We use about two million matching query-target pairs and about one million random items for training, validation and testing in the proportion of 80%, 10%, %10. We randomly select a million products from the catalog, forming a distractor set, which is then mixed with the true targets in the test dataset. The objective of evaluation is to determine, for known matching query-target pairs, the percentage of times the true targets are among the top 10 retrieved items for their respective queries inthe embedding space using dot product (Recall@10). The higher the score, the better. Table 1 shows that two embedding models, called SIMO-128 and SISO-128, achieve comparable Recall@10 scores. The SIMO-128 model generates three 128 dimensional embeddings in one shot, while the SISO-128 generates the same three 128-dimensional embeddings but in three separate runs. The efficiency advantage of SIMO-128 implies that we can generate embeddings for the entire catalog much faster without sacrificing embedding quality.
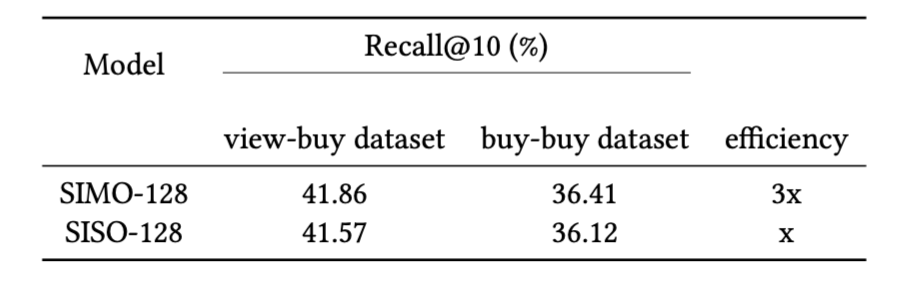
Table 1: Recall@K on view-buy and buy-buy datasets. The SIMO-128 model performs comparably to the SISO-128 model while being 3 times more efficient during inference.
The performance scores in Table 1 are computed from an encoder model that generates 128-dimensional embeddings. What happens if we use larger dimensions? Table 2 provides the answer to that question. When we increase the dimensionality of embeddings without altering any other aspect, larger dimensional vectors tend to produce higher quality embeddings, up to a certain limit.
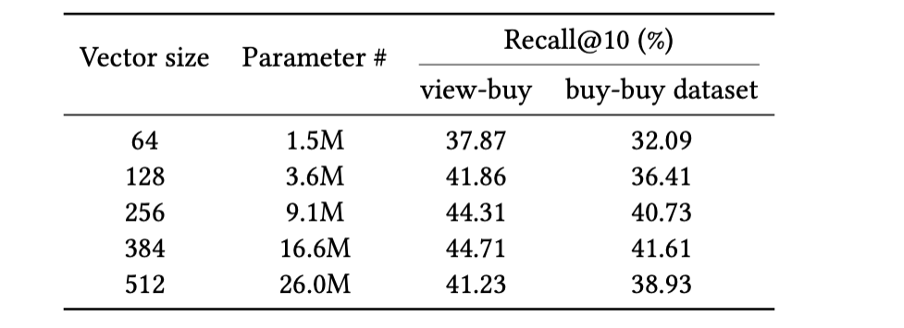
Table 2: Impact of hidden dimension vector size on Recall@K. Keeping other elements of the model the same and increasing only the hidden dimension leads to increased performance until a certain limit.
One challenging aspect in Pfeed is handling query-item pairs with complex relations (1-to-many, many-to-one, and many-to-many). An example is a diaper purchase.
There are quite a few items that are equally likely to be purchased along with or shortly before/after the purchase of diaper items such as baby clothes and toys.
Such complex query-item relations are harder to capture with embeddings. Table 3 shows Recall@10 scores for different levels of relationship complexity. Performance on query-to-item with complex relations is lower than those with simple relations (1-to-1 relation).
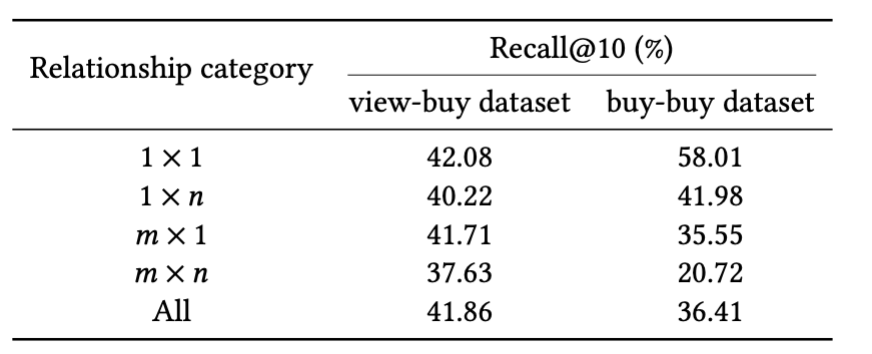
Table 3: Retrieval performance is higher on test data with simple 1 x 1 relations than with complex relations (1 x n, m x 1 and m x n relations).
Online experiment
We ran an online experiment to evaluate the business impact of Pfeed. We compared a treatment group receiving personalized Top deals for you item lists (generated by Pfeed) against a control group that received a non-personalized Top deals list, curated by promotion specialists.
This experiment was conducted over a two-week period with an even 50- 50 split between the two groups. Personalized top deals recommendations lead to a 27% increase in engagement (wish list additions) and a 4.9% uplift in conversion compared to expert-curated non-personalized top deals recommendations (See Table 4).

Table 4: Personalized top deals recommendations lead to a 27% increase in engagement (wish list additions) and a 4.9% uplift in conversion compared to expert-curated non-personalized top deals recommendations.
Conclusions and future work
We introduced Pfeed, a method deployed at Bol for generating personalized product feeds: Top deals for you, Top picks for you, New for you, and Select deals for you. Pfeed uses a query-to-item framework, which differs from the dominant user-item framework in personalized recommender systems. We highlighted three benefits: 1) Simplified real-time deployment. 2) Improved interpretability. 3) Enhanced computational efficiency.
Future work on Pfeed will focus on expanding the model embedding capabilities to handle complex query-to-item relations such as that of diaper items being co-purchased with diverse other baby items. Second line of future work can focus on handling explicit modelling of generalization and memorization of relations, adaptively choosing either approach based on frequency. Frequently occurring query-to-item pairs could be memorized and those that involve tail items (low frequency or newly released items) could be modelled based on content features such as title and descriptions. Currently, Pfeed only uses content for modelling both head and tail items.
If this type of work inspires you or you are looking for new challenges, consider checking for available opportunities on bol’s careers website.
Acknowledgements
We thank Nick Tinnemeier and Eryk Lewinson for feedback on this post.