
Underfitting is a common issue encountered during the development of machine learning (ML) models. It occurs when a model is unable to effectively learn from the training data, resulting in subpar performance. In this article, we’ll explore what underfitting is, how it happens, and the strategies to avoid it.
Table of contents
What is underfitting?
Underfitting is when a machine learning model fails to capture the underlying patterns in the training data, leading to poor performance on both the training and test data. When this occurs it means that the model is too simple and doesn’t do a good job of representing the data’s most important relationships. As a result, the model struggles to make accurate predictions on all data, both data seen during training and any new, unseen data.
How does underfitting happen?
Underfitting occurs when a machine learning algorithm produces a model that fails to capture the most important properties of the training data; models that fail in this way are considered to be too simple. For instance, imagine you’re using linear regression to predict sales based on marketing spend, customer demographics, and seasonality. Linear regression assumes the relationship between these factors and sales can be represented as a mix of straight lines.
Although the actual relationship between marketing spend and sales may be curved or include multiple interactions (e.g., sales increasing rapidly at first, then plateauing), the linear model will oversimplify by drawing a straight line. This simplification misses important nuances, leading to poor predictions and overall performance.
This issue is common in many ML models where high bias (rigid assumptions) prevents the model from learning essential patterns, causing it to perform poorly on both the training and test data. Underfitting is typically seen when the model is too simple to represent the true complexity of the data.
Underfitting vs. overfitting
In ML, underfitting and overfitting are common issues that can negatively affect a model’s ability to make accurate predictions. Understanding the difference between the two is crucial for building models that generalize well to new data.
- Underfitting occurs when a model is too simple and fails to capture the key patterns in the data. This leads to inaccurate predictions for both the training data and new data.
- Overfitting happens when a model becomes overly complex, fitting not only the true patterns but also the noise in the training data. This causes the model to perform well on the training set but poorly on new, unseen data.
To better illustrate these concepts, consider a model that predicts athletic performance based on stress levels. The blue dots in the chart represent the data points from the training set, while the lines show the model’s predictions after being trained on that data.

1
Underfitting: In this case, the model uses a simple straight line to predict performance, even though the actual relationship is curved. Since the line doesn’t fit the data well, the model is too simple and fails to capture important patterns, resulting in poor predictions. This is underfitting, where the model fails to learn the most useful properties of the data.
2
Optimal fit: Here, the model fits the curve of the data appropriately enough. It captures the underlying trend without being overly sensitive to specific data points or noise. This is the desired scenario, where the model generalizes reasonably well and can make accurate predictions on similar, new data. However, generalization can still be challenging when faced with vastly different or more complex datasets.
3
Overfitting: In the overfitting scenario, the model closely follows almost every data point, including noise and random fluctuations in the training data. While the model performs extremely well on the training set, it is too specific to the training data, and so will be less effective when predicting new data. It struggles to generalize and will likely make inaccurate predictions when applied to unseen scenarios.
Common causes of underfitting
There are many potential causes of underfitting. The four most common are:
- Model architecture is too simple.
- Poor feature selection
- Insufficient training data
- Not enough training
Let’s dig into these a bit further to understand them.
Model architecture is too simple
Model architecture refers to the combination of the algorithm used to train the model and the model’s structure. If the architecture is too simple, it might have trouble capturing the high-level properties of the training data, leading to inaccurate predictions.
For example, if a model tries to use a single straight line to model data that follows a curved pattern, it will consistently underfit. This is because a straight line cannot accurately represent the high-level relationship in curved data, making the model’s architecture inadequate for the task.
Poor feature selection
Feature selection involves choosing the right variables for the ML model during training. For example, you might ask an ML algorithm to look at a person’s birth year, eye color, age, or all three when predicting if a person will hit the buy button on an e-commerce website.
If there are too many features, or the selected features don’t correlate strongly with the target variable, the model won’t have enough relevant information to make accurate predictions. Eye color might be irrelevant to conversion, and age captures much of the same information as birth year.
Insufficient training data
When there are too few data points, the model may underfit because the data does not capture the most important properties of the problem. This can happen either due to a lack of data or because of sampling bias, where certain data sources are excluded or underrepresented, preventing the model from learning important patterns.
Not enough training
Training an ML model involves adjusting its internal parameters (weights) based on the difference between its predictions and the actual outcomes. The more training iterations the model undergoes, the better it can adjust to fit the data. If the model is trained with too few iterations, it may not have enough opportunities to learn from the data, leading to underfitting.
How to detect underfitting
One way to detect underfitting is by analyzing the learning curves, which plot the model’s performance (typically loss or error) against the number of training iterations. A learning curve shows how the model improves (or fails to improve) over time on both the training and validation datasets.
The loss is the magnitude of the model’s error for a given set of data. Training loss measures this for the training data and validation loss for the validation data. Validation data is a separate dataset used to test the model’s performance. It is usually produced by randomly splitting a larger dataset into training and validation data.
In the case of underfitting, you will notice the following key patterns:
- High training loss: If the model’s training loss remains high and flatlines early in the process, it suggests that the model is not learning from the training data. This is a clear sign of underfitting, as the model is too simple to adapt to the complexity of the data.
- Similar training and validation loss: If both the training and validation loss are high and remain close to each other throughout the training process, it means the model is underperforming on both datasets. This indicates that the model is not capturing enough information from the data to make accurate predictions, which points to underfitting.
Below is an example chart showing learning curves in an underfitting scenario:
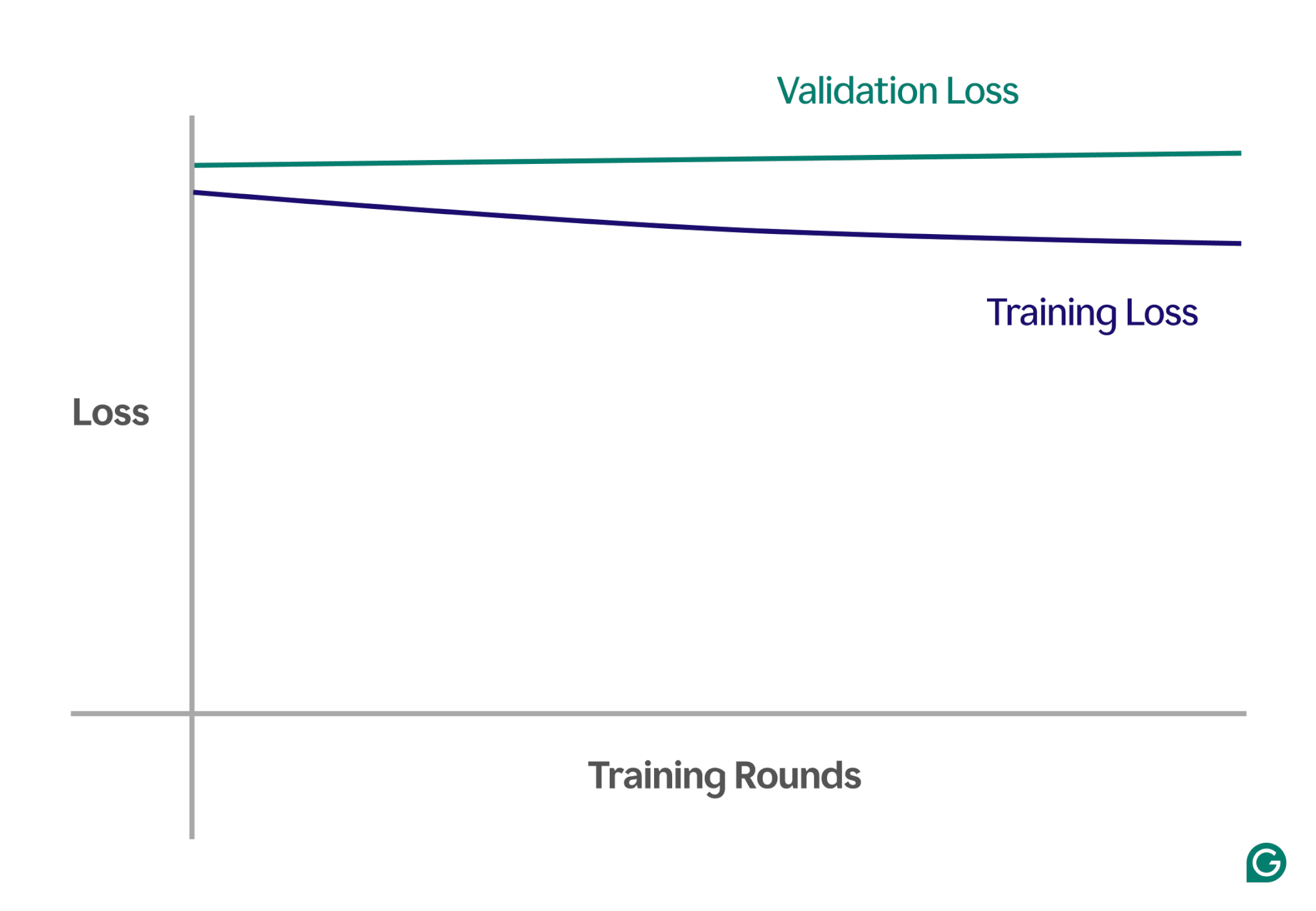
In this visual representation, underfitting is easy to spot:
- In a well-fitting model, the training loss decreases significantly while the validation loss follows a similar pattern, eventually stabilizing.
- In an underfitted model, both the training and validation loss start high and stay high, without any significant improvement.
By observing these trends, you can quickly identify whether the model is too simplistic and needs adjustments to increase its complexity.
Techniques to prevent underfitting
If you encounter underfitting, there are several strategies you can use to improve the model’s performance:
- More training data: If possible, obtain additional training data. More data gives the model additional opportunities to learn patterns, provided the data is of high quality and relevant to the problem at hand.
- Expand feature selection: Add to the model features that are more relevant. Choose features that have a strong relationship to the target variable, giving the model a better chance to capture important patterns that were previously missed.
- Increase architectural power: In models based on neural networks, you can adjust the architectural structure by changing the number of weights, layers, or other hyperparameters. This can allow the model to be more flexible and more easily find the high-level patterns in the data.
- Choose a different model: Sometimes, even after tuning hyperparameters, a specific model may not be well suited to the task. Testing multiple model algorithms can help find a more appropriate model and improve performance.
Practical examples of underfitting
To illustrate the effects of underfitting, let’s look at real-world examples across various domains where models fail to capture the complexity of the data, leading to inaccurate predictions.
Predicting house prices
To accurately predict the price of a house, you need to consider many factors, including location, size, type of house, condition, and number of bedrooms.
If you use too few features—such as only the size and type of the house—the model won’t have access to critical information. For example, the model might assume a small studio is inexpensive, without knowing it is located in Mayfair, London, an area with high property prices. This leads to poor predictions.
To resolve this, data scientists must ensure proper feature selection. This involves including all relevant features, excluding irrelevant ones, and using accurate training data.
Speech recognition
Voice recognition technology has become increasingly common in daily life. For instance, smartphone assistants, customer service helplines, and assistive technology for disabilities all use speech recognition. When training these models, data from speech samples and their correct interpretations are used.
To recognize speech, the model converts sound waves captured by a microphone into data. If we simplify this by only providing the dominant frequency and volume of the voice at specific intervals, we reduce the amount of data the model must process.
However, this approach strips away essential information needed to fully understand the speech. The data becomes too simplistic to capture the complexity of human speech, such as variations in tone, pitch, and accent.
As a result, the model will underfit, struggling to recognize even basic word commands, let alone complete sentences. Even if the model is sufficiently complex, the lack of comprehensive data leads to underfitting.
Image classification
An image classifier is designed to take an image as input and output a word to describe it. Let’s say you’re building a model to detect whether an image contains a ball or not. You train the model using labeled images of balls and other objects.
If you mistakenly use a simple two-layer neural network instead of a more suitable model like a convolutional neural network (CNN), the model will struggle. The two-layer network flattens the image into a single layer, losing important spatial information. Additionally, with only two layers, the model lacks the capacity to identify complex features.
This leads to underfitting, as the model will fail to make accurate predictions, even on the training data. CNNs solve this issue by preserving the spatial structure of images and using convolutional layers with filters that automatically learn to detect important features like edges and shapes in the early layers and more complex objects in the later layers.