
Hasn’t everyone wished, at some point or another, that their phone keyboard understood them a little better? We’ve all experienced typing a word that we use frequently—our pet’s nickname or the name of a project at work—only to have our keyboard not recognize this term and give us an unhelpful correction instead.
Today, the Grammarly Keyboard on iOS can learn your personal lexicon, tailoring suggestions to the words you use, even if they’re not in the standard dictionary. In this post, we’ll explain how we built the model that powers this functionality, which runs entirely on the device, in a performant, accurate way.
Before – User typing their custom vocabulary for the first time.
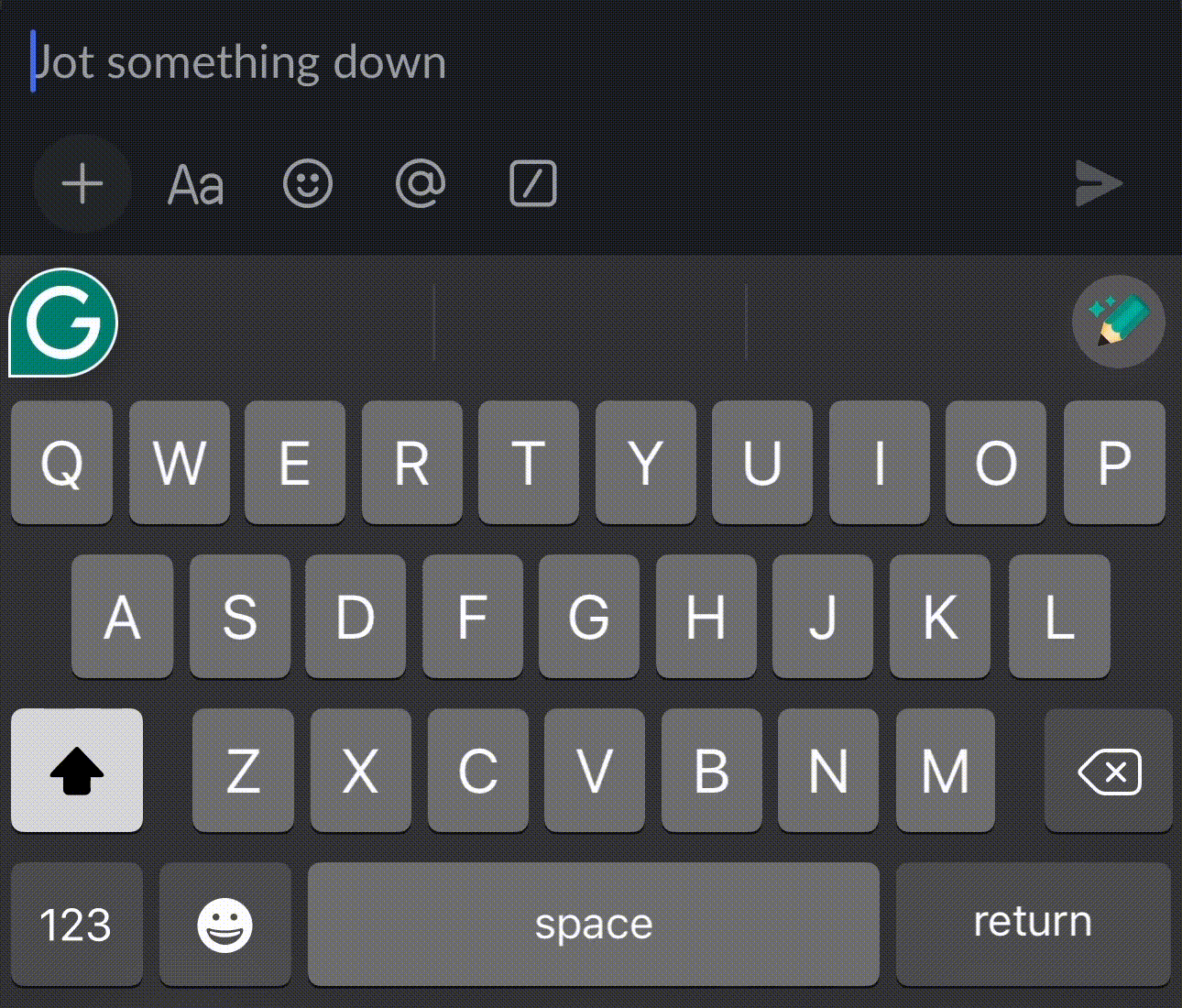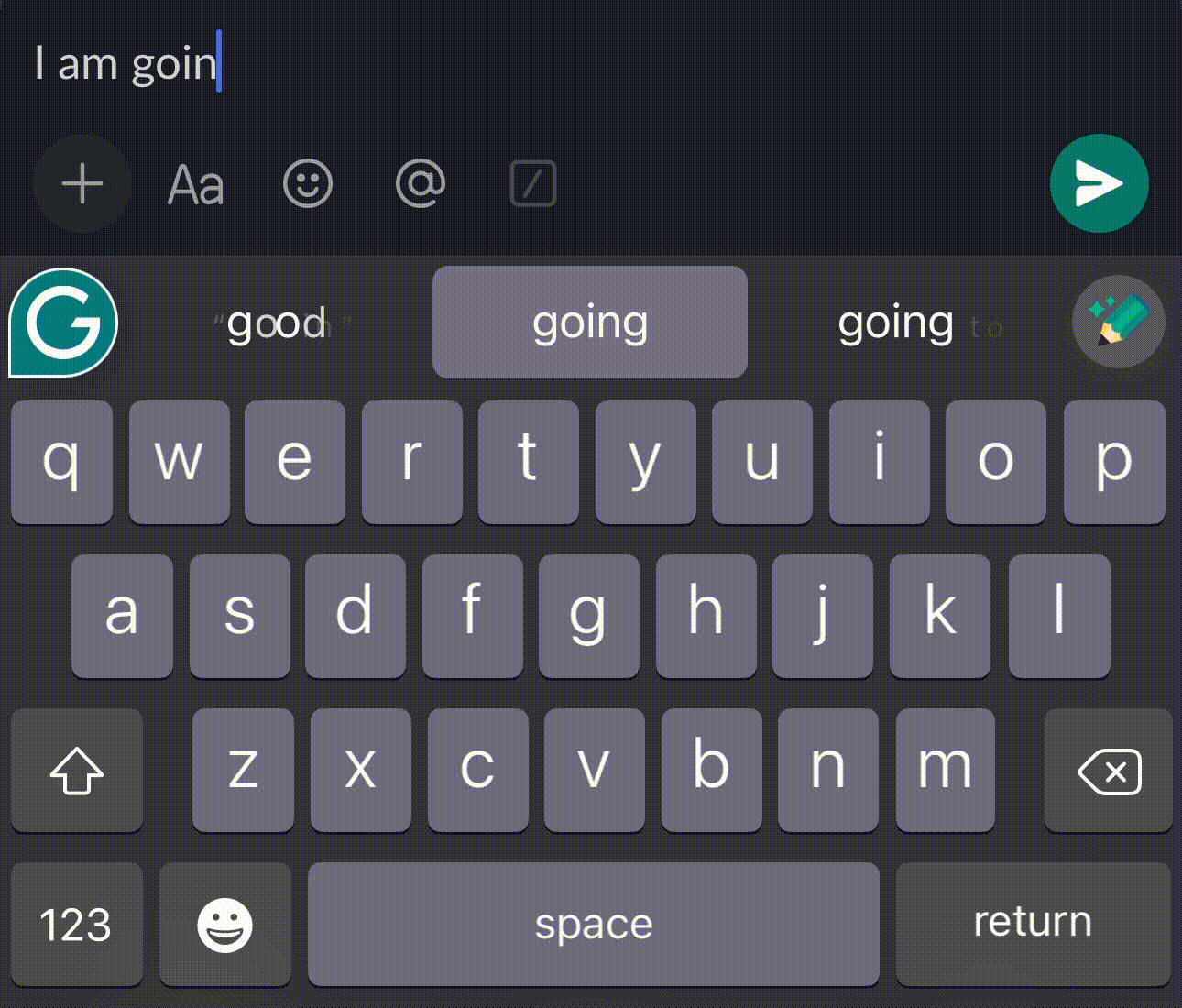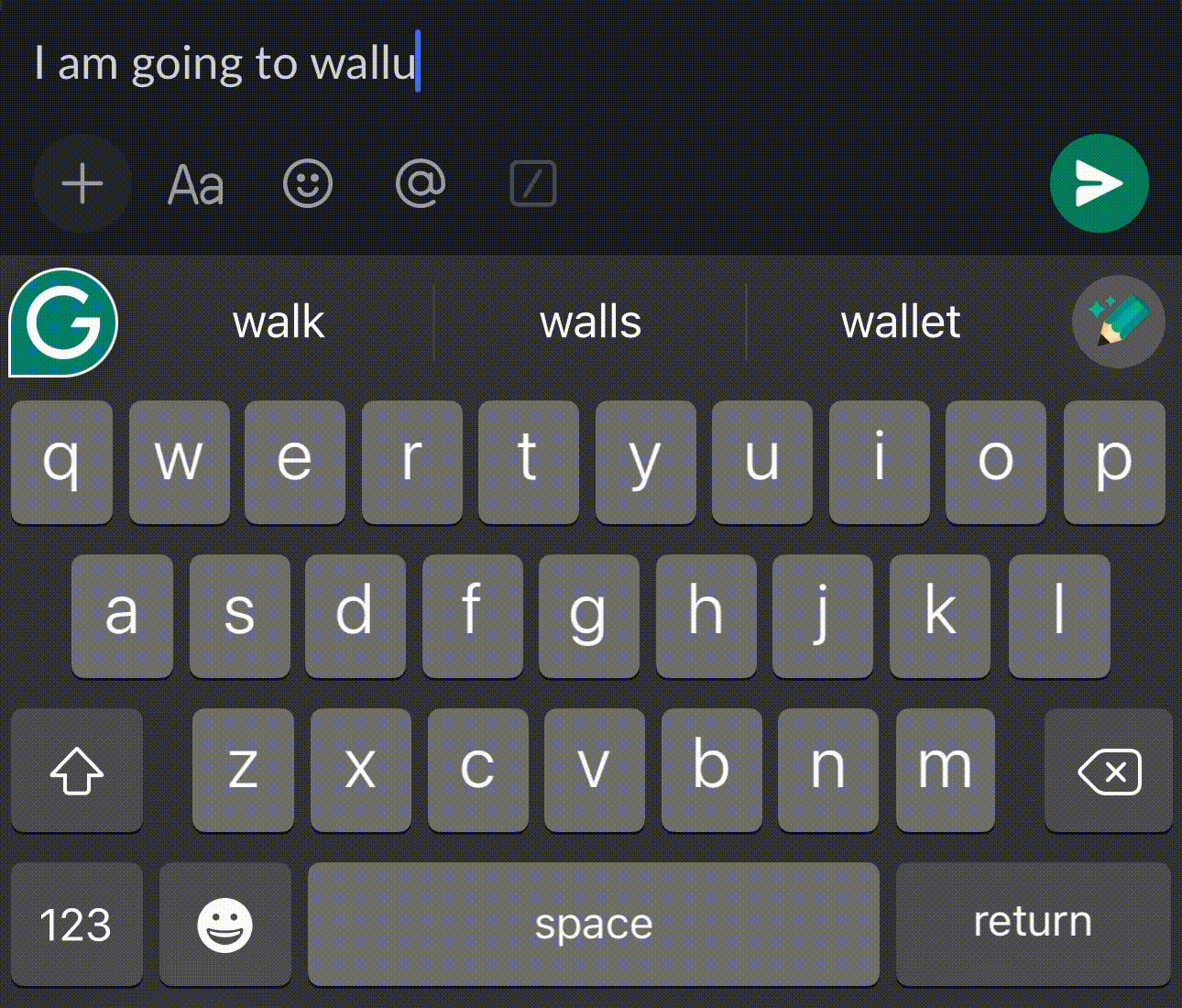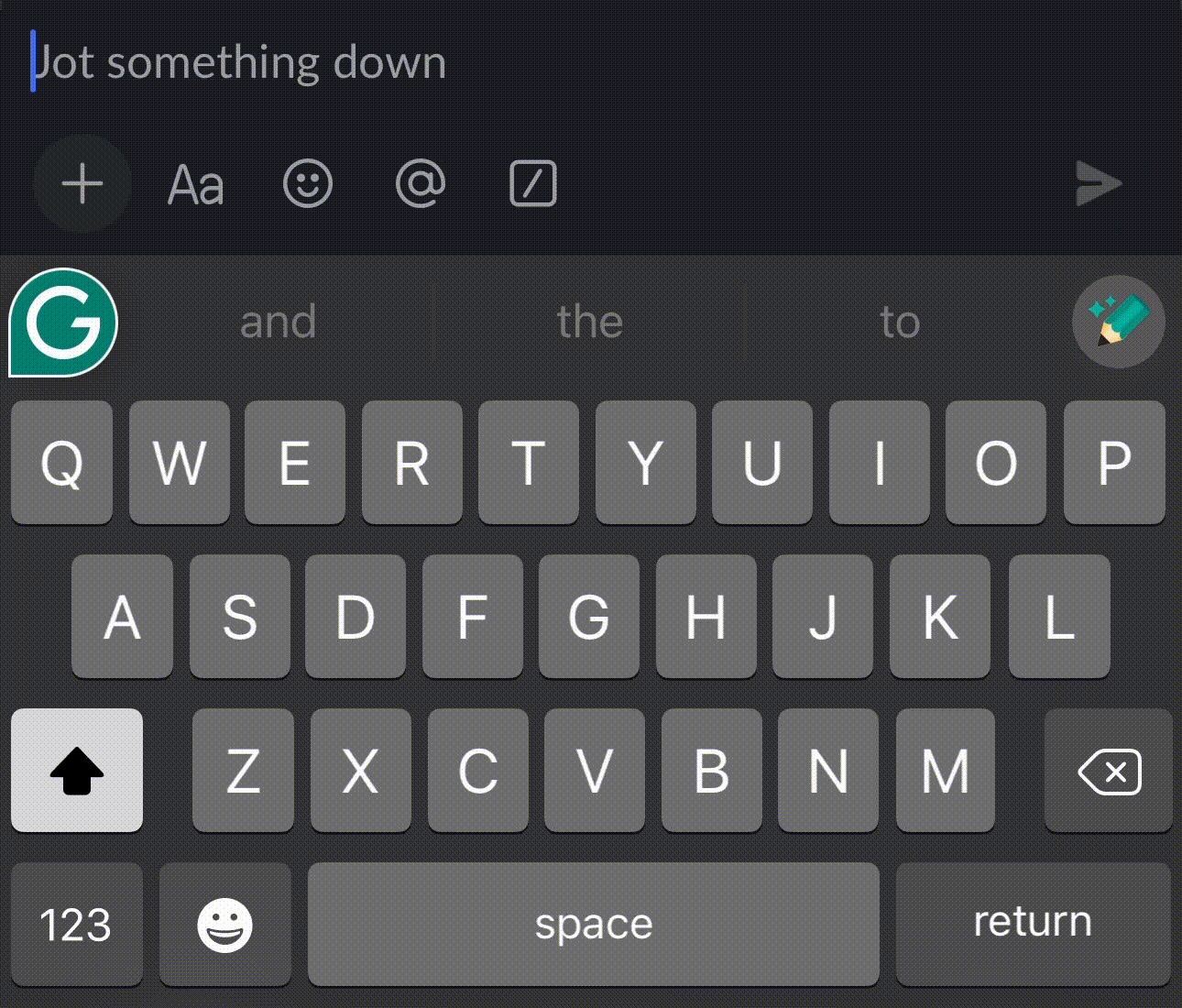
After – PLM learned the user vocabulary and auto-corrected words.
Why on device?
While personalization can improve communication, it should never come at the expense of privacy. At Grammarly, we are committed to ensuring that users always control their data. Given that we’re modeling personal vocabulary, we built the model entirely on the device so that sensitive data would never leave the device or be exposed to third parties.
Building the model on the device has additional benefits when compared to a traditional cloud-based model. Since it doesn’t rely on connectivity to function, users will always have access to personalized suggestions, regardless of the stability of their connection. Furthermore, we won’t have to do any complex syncing with the server (as in the case of a hybrid model that splits processing between the cloud and the device).
That said, there are several challenges with building an on-device model, which we’ll discuss next.
Maximizing performance
The average mobile device has 4 GB of RAM, of which only ~70 MB can be used by the keyboard at any given time. The Grammarly Keyboard already uses 60 MB for core functionality, leaving less than 5 MB for new features. What’s more, keyboard performance really matters—the user will acutely feel any lags when typing.
We do a few things to ensure that our personalized model doesn’t slow down (or crash) the keyboard. First, we store the model in persistent memory and use a memory-mapped key-value store to retrieve relevant n-grams into RAM on an on-demand basis. We also cache recurring computations, enabling efficient cold and warm start times. Finally, we limit the size of the number of unigrams and n-grams in the custom vocabulary dictionary to avoid bloating the device’s persistent memory storage.
The limited custom vocabulary dictionary required us to thoughtfully manage the process of adding new words. Specifically, we needed to distinguish between obsolete words (that we should forget) and relevant words (that we should keep). We did this by applying a time-based decay function that dynamically adjusted word probabilities based on how recently the word was used. When the dictionary gets full, we delete the least-used words (as calculated by the function) to create space for new words.
Improving accuracy
In addition to performance, we focused on delivering accurate suggestions. This proved difficult, as no reference dictionary exists for a user’s personal lexicon. Therefore, when we encountered a new word, we needed to distinguish if it was valid vocabulary or a typo. For example, let’s say you’re texting hello to your dad, whom you sometimes refer to as “pops.” You’ve typed “heeyyy pops.” Should we learn heeyyy and pops as new words?
We tackled this problem by first addressing noisy inputs. Noisy inputs are casual versions of actual words—they might include extra vowels or consonants to convey tone (“awwwww”), have missing apostrophes (“cant”), or use incorrect capitalization (“i agree”). We excluded these inputs from our learning process to meet our users’ expectations for high-quality, professional suggestions. We use a combination of regex filters and specific rules to identify noisy inputs. Only inputs that aren’t flagged as noisy are learned by the model. (In the example above, we would categorize heeyyy as casual due to the extra letters, and our model wouldn’t learn this input.)
The previous approach doesn’t fully address the question of whether to learn and suggest words like pops. While various strategies exist, we opted for a simple trust-but-verify method. This involves learning every new word but deferring suggestions until the word appears enough times. Specifically, we use edit-distance-based frequency thresholding to determine when the candidate has met the necessary criteria to go from learning to suggesting. This method lets us distinguish quality new words from noise without requiring expensive operations.
To evaluate the efficacy of our approach, we built an offline evaluation framework to simulate production behavior. This allowed us to validate that the model handled potential edge cases properly and identify potential errors to fix before they affected customers. In fact, that’s how we discovered that we weren’t handling inputs like “dont” or “cant” properly, which led to creating new regex filters. Surprisingly, the framework also validated that the model did a great job learning common proper nouns (like iTunes) that weren’t part of the default dictionary.
Impact
We’ve shipped the personalized model to over 5 million mobile devices via the Grammarly Keyboard. Notably, it’s already having a sizable positive impact on our ecosystem.
Through our aggregated logging metrics, we’ve observed a significant decrease in the rate of reverted suggestions and a slight increase in the rate of accepted suggestions. This indicates that we’re solving the problem we set out to fix—users are getting fewer irrelevant suggestions that they need to revert, which indicates that we’re doing a better job modeling how they communicate. Our internal performance metrics also show that the model operates with minimal RAM usage and efficient cold and warm start times, signaling that the keyboard app is responsive.
Takeaways
Creating personalized lexicons on devices marks a significant milestone in Grammarly’s mission to empower users to communicate more effectively and prioritize their privacy. Through advanced strategies like adaptive algorithms and good old trial and error, we’ve uncovered how to learn a user’s personal lexicon without requiring cloud computing power. If you are excited about building models that power better digital communication, we’d love to hear from you. Check out our job openings here.
Special thanks to the entire team that worked on this project: Sri Malireddi, Suwen Zhu, Kosta Eleftheriou, Dhruv Matani, Roman Tysiachnik, Oleksandr Ivashchenko, Illia Dzivinskyi, Ignat Blazhko, Ankit Garg, John Blatz, and Max Gubin.