
Generative adversarial networks (GANs) are a powerful artificial intelligence (AI) tool with numerous applications in machine learning (ML). This guide explores GANs, how they work, their applications, and their advantages and disadvantages.
Table of contents
What is a generative adversarial network?
A generative adversarial network, or GAN, is a type of deep learning model typically used in unsupervised machine learning but also adaptable for semi-supervised and supervised learning. GANs are used to generate high-quality data similar to the training dataset. As a subset of generative AI, GANs are composed of two submodels: the generator and the discriminator.
1
Generator: The generator creates synthetic data.
2
Discriminator: The discriminator evaluates the output of the generator, distinguishing between real data from the training set and synthetic data created by the generator.
The two models engage in a competition: the generator tries to fool the discriminator into classifying generated data as real, while the discriminator continually improves its ability to detect synthetic data. This adversarial process continues until the discriminator can no longer distinguish between real and generated data. At this point, the GAN is capable of generating realistic images, videos, and other types of data.
GANs vs. CNNs
GANs and convolutional neural networks (CNNs) are powerful types of neural networks used in deep learning, but they differ significantly in terms of use cases and architecture.
Use cases
- GANs: Specialize in generating realistic synthetic data based on training data. This makes GANs well suited for tasks like image generation, image style transfer, and data augmentation. GANs are unsupervised, meaning that they can be applied to scenarios where labeled data is scarce or unavailable.
- CNNs: Primarily used for structured data classification tasks, such as sentiment analysis, topic categorization, and language translation. Due to their classification abilities, CNNs also serve as good discriminators in GANs. However, because CNNs require structured, human-annotated training data, they are limited to supervised learning scenarios.
Architecture
- GANs: Consist of two models—a discriminator and a generator—that engage in a competitive process. The generator creates images, while the discriminator evaluates them, pushing the generator to produce increasingly realistic images over time.
- CNNs: Utilize layers of convolutional and pooling operations to extract and analyze features from images. This single-model architecture focuses on recognizing patterns and structures within the data.
Overall, while CNNs are focused on analyzing existing structured data, GANs are geared toward creating new, realistic data.
How GANs work
At a high level, a GAN works by pitting two neural networks—the generator and the discriminator—against each other. GANs don’t require a particular kind of neural network architecture for either of their two components, as long as the selected architectures complement each other. For example, if a CNN is used as a discriminator for image generation, then the generator might be a de-convolutional neural network (deCNN), which performs the CNN process in reverse. Each component has a different goal:
- Generator: To produce data of such high quality that the discriminator is fooled into classifying it as real.
- Discriminator: To accurately classify a given data sample as real (from the training dataset) or fake (generated by the generator).
This competition is an implementation of a zero-sum game, where a reward given to one model is also a penalty for the other model. For the generator, successfully fooling the discriminator results in a model update that enhances its ability to generate realistic data. Conversely, when the discriminator correctly identifies fake data, it receives an update that improves its detection capabilities. Mathematically, the discriminator aims to minimize classification error, while the generator seeks to maximize it.
The GAN training process
Training GANs involves alternating between the generator and discriminator over multiple epochs. Epochs are complete training runs over the entire dataset. This process continues until the generator produces synthetic data that deceives the discriminator around 50% of the time. While both models use similar algorithms for performance evaluation and improvement, their updates happen independently. These updates are carried out using a method called backpropagation, which measures each model’s error and adjusts parameters to improve performance. An optimization algorithm then adjusts each model’s parameters independently.
Here’s a visual representation of the GAN architecture, illustrating the competition between the generator and discriminator:
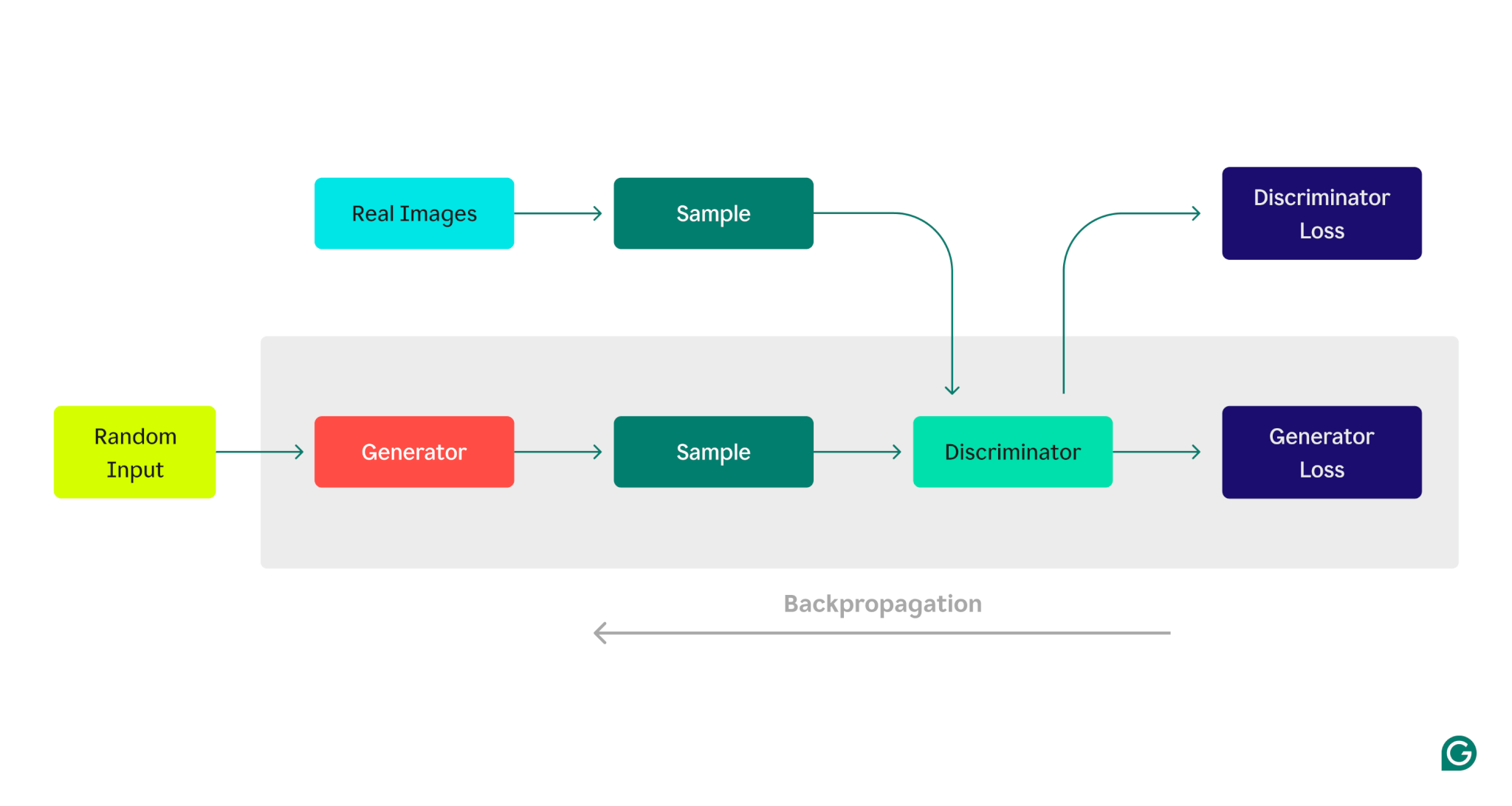
Generator training phase:
1
The generator creates data samples, typically starting with random noise as input.
2
The discriminator classifies these samples as real (from the training dataset) or fake (generated by the generator).
3
Based on the discriminator’s response, the generator parameters are updated using backpropagation.
Discriminator training phase:
1
Fake data is generated using the current state of the generator.
2
The generated samples are provided to the discriminator, along with samples from the training dataset.
3
Using backpropagation, the discriminator’s parameters are updated based on its classification performance.
This iterative training process continues, with each model’s parameters being adjusted based on its performance, until the generator consistently produces data that the discriminator cannot reliably distinguish from real data.
Types of GANs
Building on the basic GAN architecture often referred to as a vanilla GAN, other specialized types of GANs have been developed and optimized for various tasks. Some of the most common variations are described below, though this is not an exhaustive list:
Conditional GAN (cGAN)
Conditional GANs, or cGANs, use additional information, called conditions, to guide the model in generating specific types of data when training on a more general dataset. A condition can be a class label, text-based description, or another type of classifying information for the data. For example, imagine that you need to generate images only of Siamese cats, but your training dataset contains images of all kinds of cats. In a cGAN, you could label training images with the type of cat, and the model could use this to learn how to generate only pictures of Siamese cats.
Deep convolutional GAN (DCGAN)
A deep convolutional GAN, or DCGAN, is optimized for image generation. In a DCGAN, the generator is a deep embedding convolutional neural network (deCNN), and the discriminator is a deep CNN. CNNs are better suited for working with and generating images due to their ability to capture spatial hierarchies and patterns. The generator in a DCGAN uses upsampling and transposed convolutional layers to create higher-quality images than a multilayered perceptron (a simple neural network that makes decisions by weighing input features) could generate. Similarly, the discriminator uses convolutional layers to extract features from the image samples and accurately classify them as real or fake.
CycleGAN
CycleGAN is a type of GAN designed to generate one type of image from another. For example, a CycleGAN can transform an image of a mouse into a rat, or a dog into a coyote. CycleGANs are able to perform this image-to-image translation without training on paired datasets, that is, datasets containing both the base image and the desired transformation. This capability is achieved by using two generators and two discriminators instead of the single pair that a vanilla GAN uses. In CycleGAN, one generator converts images from the base image to the transformed version, while the other generator performs a conversion in the opposite direction. Likewise, each discriminator checks a particular image type to determine if it is real or fake. CycleGAN then uses a consistency check to make sure that converting an image to the other style and back results in the original image.
Applications of GANs
Due to their distinctive architecture, GANs have been applied to a range of innovative use cases, though their performance is highly dependent on specific tasks and data quality. Some of the more powerful applications include text-to-image generation, data augmentation, and video generation and manipulation.
Text-to-image generation
GANs can generate images from a textual description. This application is valuable in creative industries, allowing authors and designers to visualize the scenes and characters described in text. While GANs are often used for such tasks, other generative AI models, like OpenAI’s DALL-E, use transformer-based architectures to achieve similar outcomes.
Data augmentation
GANs are useful for data augmentation because they can generate synthetic data that resembles real training data, though the degree of accuracy and realism can vary depending on the specific use case and model training. This capability is particularly valuable in machine learning for expanding limited datasets and enhancing model performance. Additionally, GANs offer a solution for maintaining data privacy. In sensitive fields like healthcare and finance, GANs can produce synthetic data that preserves the statistical properties of the original dataset without compromising sensitive information.
Video generation and manipulation
GANs have shown promise in certain video generation and manipulation tasks. For instance, GANs can be used to generate future frames from an initial video sequence, aiding in applications like predicting pedestrian movement or forecasting road hazards for autonomous vehicles. However, these applications are still under active research and development. GANs can also be used to generate completely synthetic video content and enhance videos with realistic special effects.
Advantages of GANs
GANs offer several distinct advantages, including the ability to generate realistic synthetic data, learn from unpaired data, and perform unsupervised training.
High-quality synthetic data generation
GANs’ architecture allows them to produce synthetic data that can approximate real-world data in applications like data augmentation and video creation, though the quality and precision of this data can depend heavily on training conditions and model parameters. For example, DCGANs, which utilize CNNs for optimal image processing, excel in generating realistic images.
Able to learn from unpaired data
Unlike some ML models, GANs can learn from datasets without paired examples of inputs and outputs. This flexibility allows GANs to be used in a broad range of tasks where paired data is scarce or unavailable. For example, in image-to-image translation tasks, traditional models often require a dataset of images and their transformations for training. In contrast, GANs can leverage a wider variety of potential datasets for training.
Unsupervised learning
GANs are an unsupervised machine learning method, meaning that they can be trained on unlabeled data without explicit direction. This is particularly advantageous because labeling data is a time-consuming and costly process. GANs’ ability to learn from unlabeled data makes them valuable for applications where labeled data is limited or difficult to obtain. GANs can also be adapted for semi-supervised and supervised learning, allowing them to also use labeled data.
Disadvantages of GANs
While GANs are a powerful tool in machine learning, their architecture creates a unique set of disadvantages. These disadvantages include sensitivity to hyperparameters, high computational costs, convergence failure, and a phenomenon called mode collapse.
Hyperparameter sensitivity
GANs are sensitive to hyperparameters, which are parameters set prior to training and not learned from the data. Examples include network architectures and the number of training examples used in a single iteration. Small changes in these parameters can significantly affect the training process and model outputs, necessitating extensive fine-tuning for practical applications.
High computational cost
Due to their complex architecture, iterative training process, and hyperparameter sensitivity, GANs often incur high computational costs. Training a GAN successfully requires specialized and expensive hardware, as well as significant time, which can be a barrier for many organizations looking to utilize GANs.
Convergence failure
Engineers and researchers can spend significant amounts of time experimenting with training configurations before they reach an acceptable rate at which the model’s output becomes stable and accurate, known as the convergence rate. Convergence in GANs can be very difficult to achieve and might not last very long. Convergence failure is when the discriminator fails to sufficiently decide between real and fake data, resulting in an accuracy of roughly 50% because it hasn’t gained the ability to identify real data, unlike the intended balance reached during successful training. Some GANs may never reach convergence and can require specialized analysis to repair.
Mode collapse
GANs are prone to an issue called mode collapse, where the generator creates a limited range of outputs and fails to reflect the diversity of real-world data distributions. This problem arises from the GAN architecture, because the generator becomes overly focused on producing data that can fool the discriminator, leading it to generate similar examples.