
Maintaining Strategic Interoperability and Flexibility
In the fast-evolving landscape of generative AI, choosing the right components for your AI solution is critical. With the wide variety of available large language models (LLMs), embedding models, and vector databases, it’s essential to navigate through the choices wisely, as your decision will have important implications downstream.
A particular embedding model might be too slow for your specific application. Your system prompt approach might generate too many tokens, leading to higher costs. There are many similar risks involved, but the one that is often overlooked is obsolescence.
As more capabilities and tools go online, organizations are required to prioritize interoperability as they look to leverage the latest advancements in the field and discontinue outdated tools. In this environment, designing solutions that allow for seamless integration and evaluation of new components is essential for staying competitive.
Confidence in the reliability and safety of LLMs in production is another critical concern. Implementing measures to mitigate risks such as toxicity, security vulnerabilities, and inappropriate responses is essential for ensuring user trust and compliance with regulatory requirements.
In addition to performance considerations, factors such as licensing, control, and security also influence another choice, between open source and commercial models:
- Commercial models offer convenience and ease of use, particularly for quick deployment and integration
- Open source models provide greater control and customization options, making them preferable for sensitive data and specialized use cases
With all this in mind, it’s obvious why platforms like HuggingFace are extremely popular among AI builders. They provide access to state-of-the-art models, components, datasets, and tools for AI experimentation.
A good example is the robust ecosystem of open source embedding models, which have gained popularity for their flexibility and performance across a wide range of languages and tasks. Leaderboards such as the Massive Text Embedding Leaderboard offer valuable insights into the performance of various embedding models, helping users identify the most suitable options for their needs.
The same can be said about the proliferation of different open source LLMs, like Smaug and DeepSeek, and open source vector databases, like Weaviate and Qdrant.
With such mind-boggling selection, one of the most effective approaches to choosing the right tools and LLMs for your organization is to immerse yourself in the live environment of these models, experiencing their capabilities firsthand to determine if they align with your objectives before you commit to deploying them. The combination of DataRobot and the immense library of generative AI components at HuggingFace allows you to do just that.
Let’s dive in and see how you can easily set up endpoints for models, explore and compare LLMs, and securely deploy them, all while enabling robust model monitoring and maintenance capabilities in production.
Simplify LLM Experimentation with DataRobot and HuggingFace
Note that this is a quick overview of the important steps in the process. You can follow the whole process step-by-step in this on-demand webinar by DataRobot and HuggingFace.
To start, we need to create the necessary model endpoints in HuggingFace and set up a new Use Case in the DataRobot Workbench. Think of Use Cases as an environment that contains all sorts of different artifacts related to that specific project. From datasets and vector databases to LLM Playgrounds for model comparison and related notebooks.
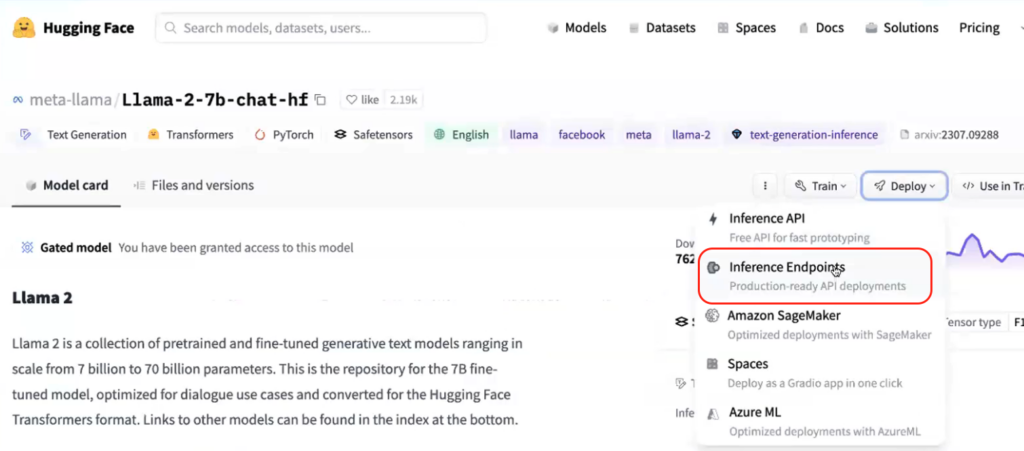
In this instance, we’ve created a use case to experiment with various model endpoints from HuggingFace.
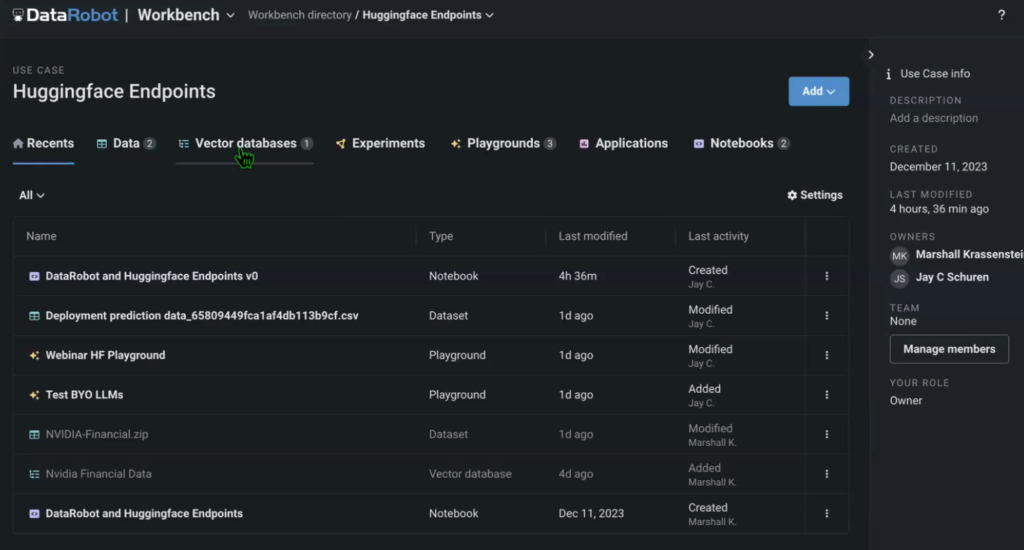
The use case also contains data (in this example, we used an NVIDIA earnings call transcript as the source), the vector database that we created with an embedding model called from HuggingFace, the LLM Playground where we’ll compare the models, as well as the source notebook that runs the whole solution.
You can build the use case in a DataRobot Notebook using default code snippets available in DataRobot and HuggingFace, as well by importing and modifying existing Jupyter notebooks.
Now that you have all of the source documents, the vector database, all of the model endpoints, it’s time to build out the pipelines to compare them in the LLM Playground.
Traditionally, you could perform the comparison right in the notebook, with outputs showing up in the notebook. But this experience is suboptimal if you want to compare different models and their parameters.
The LLM Playground is a UI that allows you to run multiple models in parallel, query them, and receive outputs at the same time, while also having the ability to tweak the model settings and further compare the results. Another good example for experimentation is testing out the different embedding models, as they might alter the performance of the solution, based on the language that’s used for prompting and outputs.
This process obfuscates a lot of the steps that you’d have to perform manually in the notebook to run such complex model comparisons. The Playground also comes with several models by default (Open AI GPT-4, Titan, Bison, etc.), so you could compare your custom models and their performance against these benchmark models.
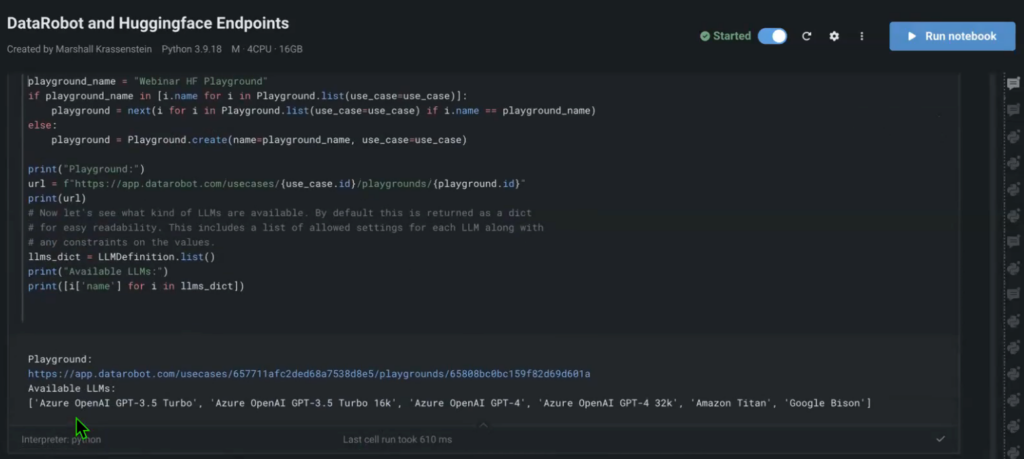
You can add each HuggingFace endpoint to your notebook with a few lines of code.
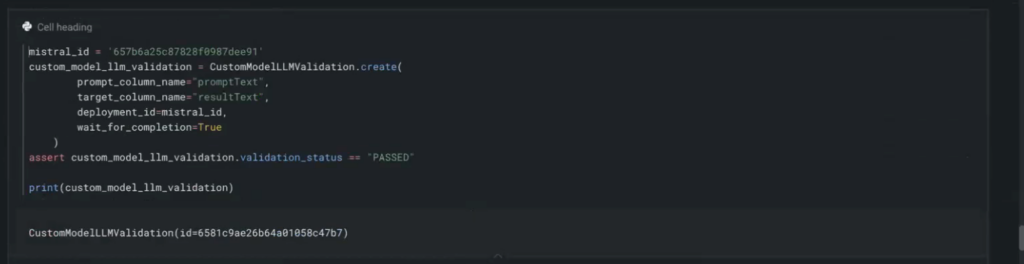
Once the Playground is in place and you’ve added your HuggingFace endpoints, you can go back to the Playground, create a new blueprint, and add each one of your custom HuggingFace models. You can also configure the System Prompt and select the preferred vector database (NVIDIA Financial Data, in this case).
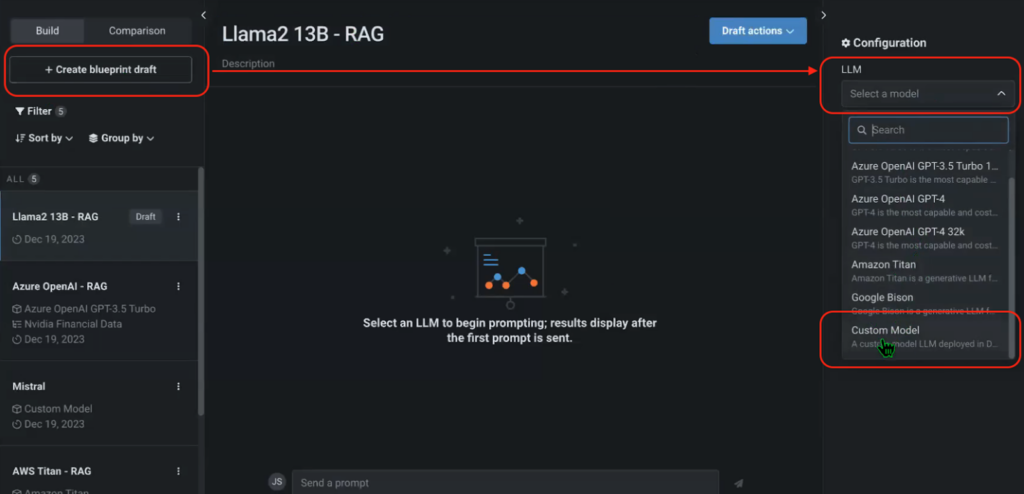
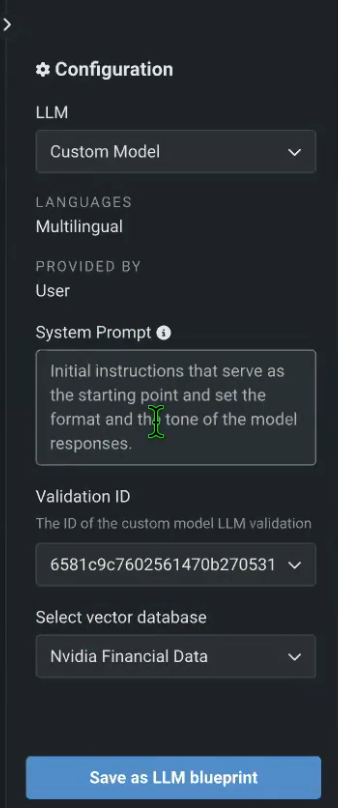
Figures 6, 7. Adding and Configuring HuggingFace Endpoints in an LLM Playground
After you’ve done this for all of the custom models deployed in HuggingFace, you can properly start comparing them.
Go to the Comparison menu in the Playground and select the models that you want to compare. In this case, we’re comparing two custom models served via HuggingFace endpoints with a default Open AI GPT-3.5 Turbo model.
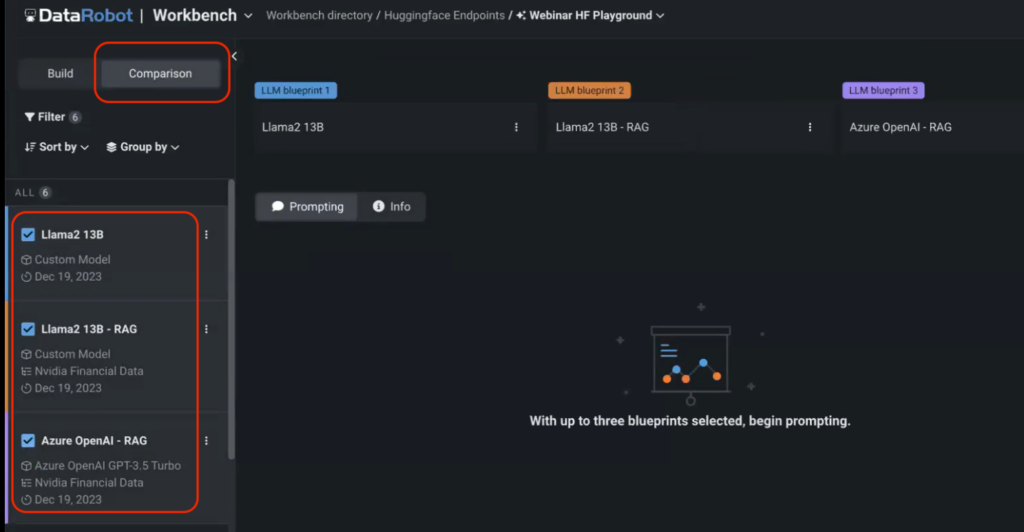
Note that we didn’t specify the vector database for one of the models to compare the model’s performance against its RAG counterpart. You can then start prompting the models and compare their outputs in real time.
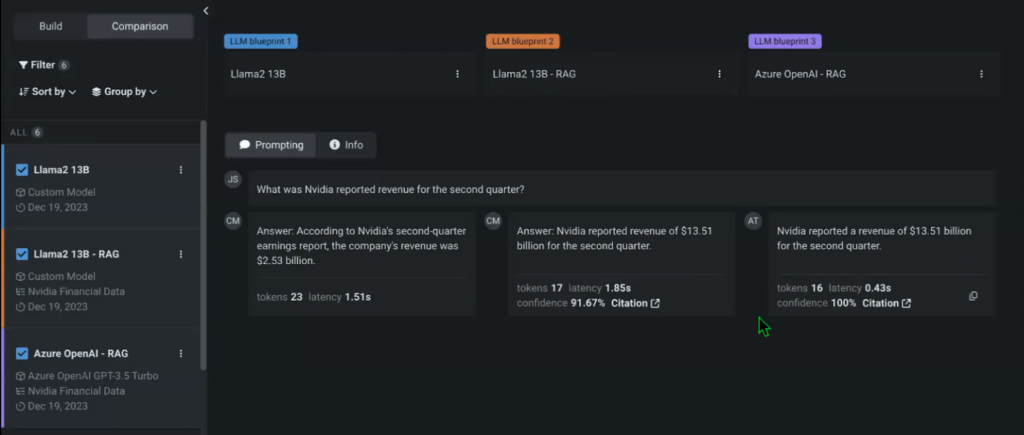
There are tons of settings and iterations that you can add to any of your experiments using the Playground, including Temperature, maximum limit of completion tokens, and more. You can immediately see that the non-RAG model that doesn’t have access to the NVIDIA Financial data vector database provides a different response that is also incorrect.
Once you’re done experimenting, you can register the selected model in the AI Console, which is the hub for all of your model deployments.
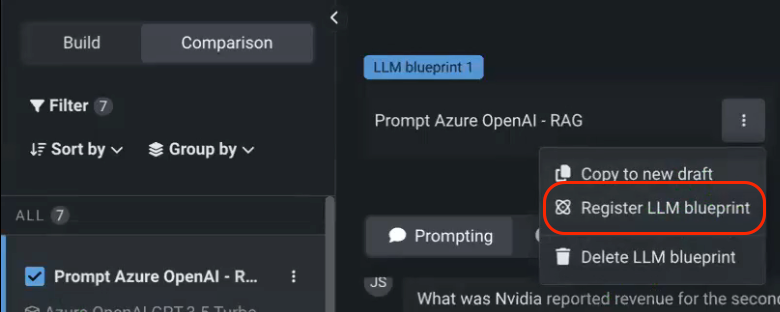
The lineage of the model starts as soon as it’s registered, tracking when it was built, for which purpose, and who built it. Immediately, within the Console, you can also start tracking out-of-the-box metrics to monitor the performance and add custom metrics, relevant to your specific use case.
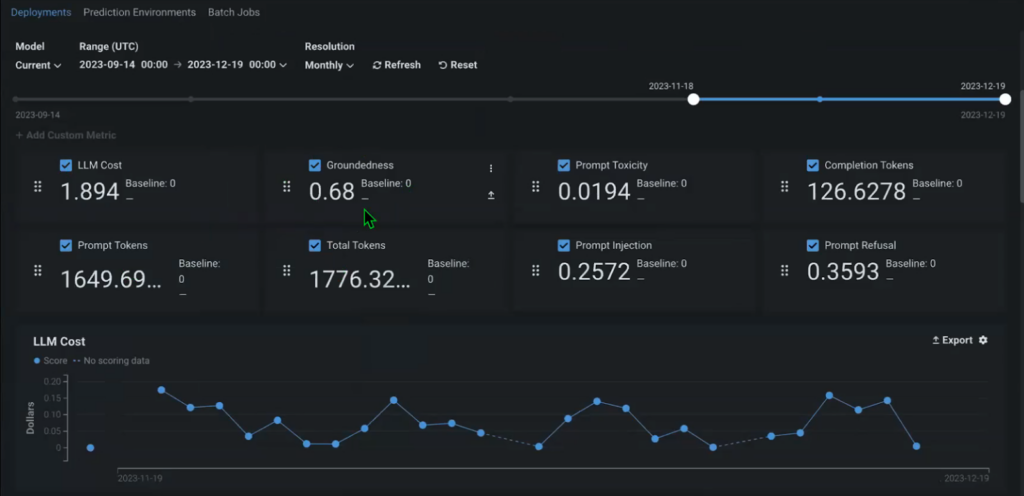
For example, Groundedness might be an important long-term metric that allows you to understand how well the context that you provide (your source documents) fits the model (what percentage of your source documents is used to generate the answer). This allows you to understand whether you’re using actual / relevant information in your solution and update it if necessary.
With that, you’re also tracking the whole pipeline, for each question and answer, including the context retrieved and passed on as the output of the model. This also includes the source document that each specific answer came from.
How to Choose the Right LLM for Your Use Case
Overall, the process of testing LLMs and figuring out which ones are the right fit for your use case is a multifaceted endeavor that requires careful consideration of various factors. A variety of settings can be applied to each LLM to drastically change its performance.
This underscores the importance of experimentation and continuous iteration that allows to ensure the robustness and high effectiveness of deployed solutions. Only by comprehensively testing models against real-world scenarios, users can identify potential limitations and areas for improvement before the solution is live in production.
A robust framework that combines live interactions, backend configurations, and thorough monitoring is required to maximize the effectiveness and reliability of generative AI solutions, ensuring they deliver accurate and relevant responses to user queries.
By combining the versatile library of generative AI components in HuggingFace with an integrated approach to model experimentation and deployment in DataRobot organizations can quickly iterate and deliver production-grade generative AI solutions ready for the real world.
About the author

Nathaniel Daly is a Senior Product Manager at DataRobot focusing on AutoML and time series products. He’s focused on bringing advances in data science to users such that they can leverage this value to solve real world business problems. He holds a degree in Mathematics from University of California, Berkeley.